Building a RAG application using LangChain and LangSmith
Table of Contents
GenAI - This article is part of a series.
Why RAG? #
LLMs have come a long way since their inception. However, one of the main problems with LLMs is that they are trained on publically available data or generic training data. This means they are not able to perform well in domain-specific scenarios. To overcome this we would either need to retrain the model with Domain-specific data which is costly or use something like RAG.
Another important need is that LLMs are known to hallucinate(generate a response that seems true but is not available in training data/factually incorrect). One of the ways to overcome this is by grounding the response with relevant reliable information.
What is RAG? #
RAG stands for Retrieval Augmented Generation. The basic principle is that when we query an LLM, we pass in relevant context with the query so that the LLM can easily respond with relevant information. We are able to do this now because the context windows which used to 2048/4096 tokens have now come a long way to around 1 Million for newer models. There are 3 basic steps in RAG,
- Indexing
- Retrieval
- Generation
We will take a simple use case and see LLMs in action. I am taking a blog post I wrote earlier using it for context, and asking a relevant question for the same. Here’s a quick diagram explaining the flow.
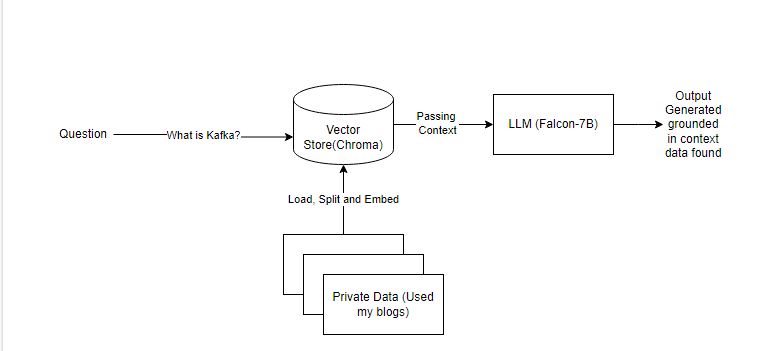
We will use LangChain, HuggingFace(Free API request), and LangSmith(for tracing) to achieve this. First, install the required modules.
! pip install langchain_community tiktoken langchainhub chromadb langchain langchain_huggingface
Create a .env file and add the API keys used in this article.
LANGCHAIN_API_KEY='<langchain-key>'
HF_TOKEN='<hf-key>'
Initialize a few environment variables, which can be set in the .env file.
import os
os.environ['LANGCHAIN_TRACING_V2'] = 'true'
os.environ['LANGCHAIN_ENDPOINT'] = 'https://api.smith.langchain.com'
Indexing #
The first step in RAG is indexing. We basically need to convert the document into a vector representation called embeddings. The reason behind this is that it’s easier to find relevance between similar pieces of text when they are in vector format. There are a few steps involved in Indexing the data.
- Loading
- Splitting
- Embedding
Loading #
LangChain offers a multitude of ways to load data. We will use a simple WebBaseLoader to load the article into memory.
# Load blog
import bs4
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader(
web_paths=("https://vignesh.page/posts/kafka/",),
bs_kwargs=dict(
# parse_only=bs4.SoupStrainer(
# class_=("main-content")
# )
),
)
blog_docs = loader.load()
blog_docs
Splitting #
We need to split the data for Embedding because there is a size limitation to how much data can be embedded in one go. We are using the RecursiveCharacterTextSplitter for our example.
# Split
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=300,
chunk_overlap=50)
# Make splits
splits = text_splitter.split_documents(blog_docs)
Indexing #
The last step is to index the data into a Vector Store. For this example, we will use an in-memory instance of Chroma. We are using the HuggingFaceEmbeddings to embed the data. We set the vector store as a retriever with k = 1 (we are using k nearest neighbors algo to find relevant documents, so 1 returns only relevant documents).
# Index
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_community.vector stores import Chroma
vector store = Chroma.from_documents(documents=splits,
embedding=HuggingFaceEmbeddings())
retriever = vectorstore.as_retriever(search_kwargs={"k": 1})
Retrieval #
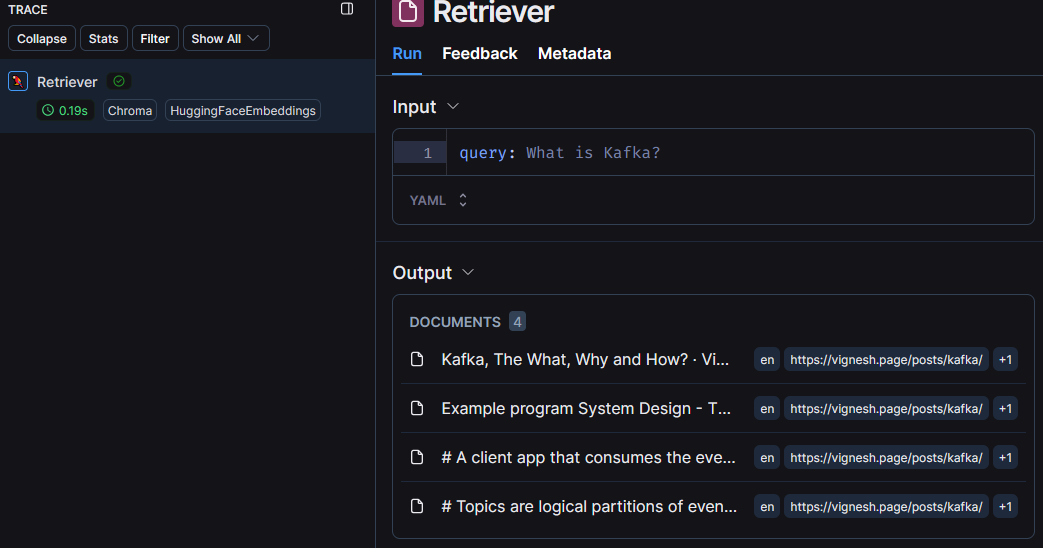
The next step is quite straightforward, we just need to retrieve relevant document chunks whenever we get a query. My query “What is Kafka?” returned 4 documents with relevant data which will be passed as context to the LLM.
docs = retriever.get_relevant_documents("What is Kafka?")
len(docs)
We can see the LangSmith trace letting us know what was retrieved.
Generation #
Now, all that is left is to pass the relevant documents to the LLM to get our response to the query.
We are using the Falcon-7B model from HuggingFace in this example, feel free to swap out with any LLM of your choice.
# LLM
from langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFace
llm = HuggingFaceEndpoint(
repo_id="tiiuae/falcon-7b",
task="text-generation",
max_new_tokens=512,
do_sample=False,
repetition_penalty=1.03,
)
Next, we create a prompt template to pass the query and the context.
from langchain.prompts import ChatPromptTemplate
# Prompt
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
We will use LangChain to chain these together and create a simple chain. Then, we invoke the chain.
# Chain
chain = prompt | llm
# Run
chain.invoke({"context":docs,"question":"What is Kafka?"})
After adding some syntactic sugar the same can be made easier to read. We will also add a default RAG prompt that is available in the LangChain hub.
from langchain import hub
prompt_hub_rag = hub.pull("rlm/rag-prompt")
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt_hub_rag
| llm
| StrOutputParser()
)
rag_chain.invoke("What is Kafka?")
We can see the trace of the execution of this chain in LangSmith as well.
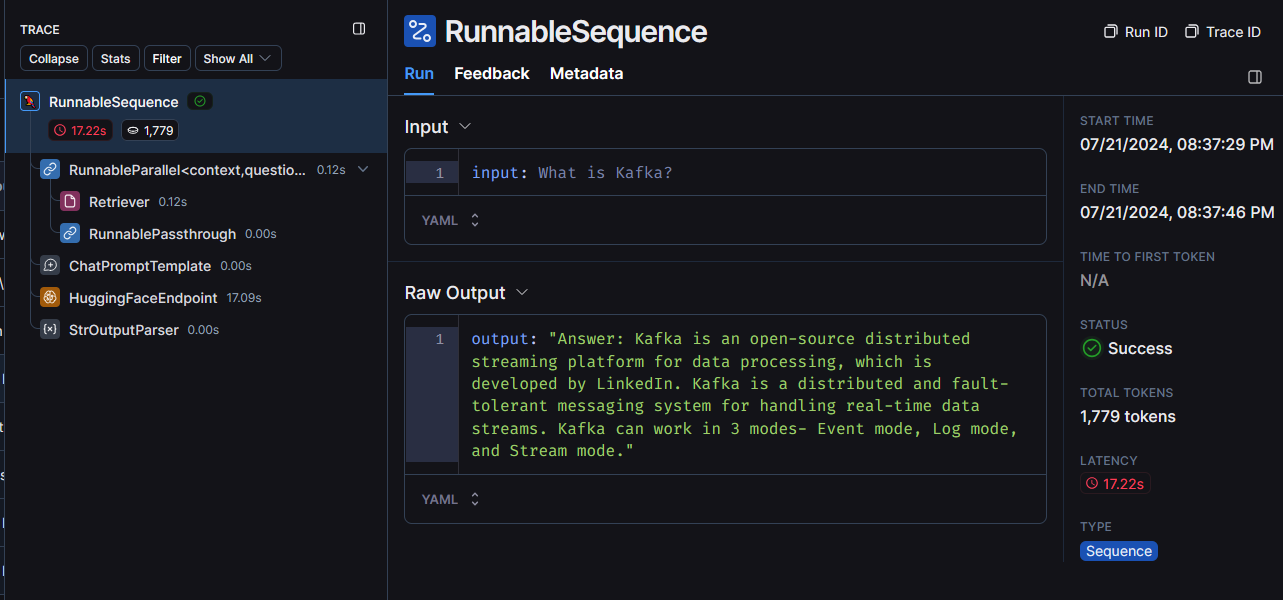
The code is available at my github. Please do give it a go. All the resources used are under the free tier making it easily accessible.
Thus with a few lines of code, we are able to build a simple RAG application. We have a multitude of tools inside LangChain that can be a separate article.